Nerea Luis: “Hay un trabajo enorme por hacer en la comunicación y en la explicabilidad de los sistemas de Inteligencia Artificial”

Nerea Luis Mingueza es doctora en Ciencias de la Computación, responsable del área de Inteligencia Artificial de Sngular y divulgadora científica, entre otros desempeños. Está siendo altamente reconocida por sus aportaciones al campo, aunque ella es tajante: queda mucho camino por recorrer en la Inteligencia Artificial y el próximo camino que debería explotarse es el de la divulgación y comunicación.
Pregunta. ¿Cuál es el objetivo de la Inteligencia Artificial?
Respuesta. Hablaría, como mínimo, de dos. En un nivel académico diría que es estudiar si es viable utilizar la informática, la computación, para generar comportamientos inteligentes. Desde una visión industrial o comercial, diría que es más encontrar casos de uso mundanos, o habituales, donde la Inteligencia Artificial pueda ejercer de potenciador o catalizador para intentar acelerar procesos. Ahí entran, por un lado, la automatización, y, por otro, la capacidad de generar conocimiento utilizando el potencial de las máquinas o modelos.
P. ¿Son compatibles la investigación y comercialización de esta tecnología?
R. Deberían serlo. Es un conflicto de madurez. La investigación no tiene un fin lucrativo, por lo que persigue romper la frontera del conocimiento. En su día, en la Conferencia de Darmouth, que fue donde se acuñó el término de Inteligencia Artificial, todas las líneas de trabajo que se acordaron iban dirigidas hacia el razonamiento y el comportamiento humano. Todo muy orientado a comprender e intentar emular la mente humana. Lo que sucede es que, cuando te llevas esta concepción al mundo empresarial, el fin lucrativo puede modificarla. De hecho, ¿cuándo se ha entendido en el mundo actual el desarrollo de este campo? Cuando se ha visto el poder económico que tienen los datos.

P. ¿El fin lucrativo no pervierte la investigación?
R. Realmente es que ha sido una cuestión de necesidad, una transición basada en la necesidad. El producto que tenían algunas compañías tecnológicas era tan grande que necesitaban ser capaces de desarrollar todas las ideas que provenían de la investigación. Solo lo podrían hacer quienes hubieran estado involucrados en el ámbito académico.
El potencial para sus nuevos desarrollos ha implicado que se hayan posicionado a favor de la investigación y quieran seguir invirtiendo en sus departamentos de investigación. Han tenido la necesidad de retroalimentarse de la investigación.
P. ¿Cuál es la idea más errónea que se tiene sobre la Inteligencia Artificial?
R. La concepción de la disciplina como una “súper inteligencia”.
No creo que sea culpa de las personas, sino más bien de la narrativa que se ha construido, pero me estoy encontrando mucha gente que piensa o relaciona la Inteligencia Artificial como una ciencia distópica que se plantea como la sustitución de los humanos.
La realidad dista mucho de esa concepción.
P. ¿Quién y cómo ha construido esa narrativa?
R. Entiendo que el imaginario y la comunicación tienen gran parte de culpa. Pienso, por ejemplo, en que en prensa lo único que se ve es un titular relacionado con un coche de Tesla que ha colisionado con varias personas. Falta un componente de divulgación.
También debemos tener en cuenta que la tecnología es un campo nuevo y, por ende, los años que se llevan educando en ciencias como puede ser la medicina, no se han dado en tecnología. Falta mucha pedagogía sobre lo que es programar, el pensamiento lógico… De aquí también el error conceptual de los “nativos digitales”. Este pensamiento generalizado que existe de que hay generaciones que, como han crecido con la tecnología en sus vidas, la controlan. Y, para nada. Tienen control como usuarios, pero de ahí a que conozcan y controlen toda la tecnología que se precisa para construir un sistema…
P. No es saber utilizar un sistema, sino qué conlleva, conocer qué consecuencias tiene…
R. Hay un trabajo enorme por hacer en la comunicación y en la explicabilidad de los sistemas.
En sistemas cuyo funcionamiento tenga un alto impacto en la vida de un humano se va a introducir un marco regulatorio.
Lo cierto es que hasta ahora nos hemos centrado mucho en el nivel técnico de los modelos, pero no hemos entendido demasiado bien cuál es el nivel usuario. Imaginemos que los algoritmos tuvieran una especie de prospecto, como los medicamentos. Un documento en el que se explique para qué está preparado el sistema, para qué no, cuál es su uso adecuado, cuáles son sus potenciales riesgos… ¡Y no estamos tan lejos de esto! A día de hoy se puede ver en una solución a la explicabilidad que construyó Google en Google Cloud Model Cards. Por ejemplo, te hablo concretamente de una que habla de cómo funciona el reconocimiento facial, dónde puede fallar, qué riesgos tiene…

P. ¿Es necesaria la legislación para que este tipo de soluciones aparezcan?
R. Totalmente. Si no se legisla, seguramente no se utilice.
Además, es importante que suceda. Utilicemos el ejemplo reciente de la viralización en Twitter de sistemas no-code (herramientas avanzadas que permiten su uso sin conocimientos de programación) basados en Inteligencia Artificial, que te permiten crear tu avatar a partir de una fotografía tuya. Estos productos se viralizan porque todo el mundo tiene acceso a ellos, pero realmente no saben cómo funcionan esos modelos y a qué sistema le están dando sus imágenes. No se habla demasiado porque no ha sucedido ningún caso que lo haya visibilizado, pero, nada quita que la empresa que ha desarrollado ese sistema después lo replique para construir un reconocimiento facial en un aeropuerto. ¿Hay una cuestión moral aquí? ¿Está bien que retengan tus datos y puedan mantenerlos en un mismo modelo para otro fin? Lo único que podemos hacer es llevar a cabo soluciones preventivas, como esta que comentamos.
Lo que se pretende es que los algoritmos que vayan a realizar acciones de fuerte impacto en la sociedad estén registrados. Igual que se puede registrar un coche, registras un código, un sistema. Aquí aparece la model card. Sería un documento necesario para registrar un sistema.
P. ¿Hay sistemas que se pueden utilizar para una aplicación, pero no para otra?
R. Este es un tema candente ahora en el sector. Ha habido casos en los que, auditando, se ha descubierto que un algoritmo que estaba funcionando en una entidad del ámbito financiero había pasado a utilizarse para una institución educativa. Bueno, es sencillo entender que los datos que ese algoritmo procesaba en la entidad financiera no tiene por qué procesarlos en la educativa, como, por ejemplo, los financieros, si es que hablamos de una entidad pública.
Lo que sucede es que si te vas a una empresa como Netflix, para que el sistema te recomiende un título u otro te da igual qué algoritmo usar. A efectos prácticos, el impacto que tiene esa predicción es ínfimo en tu vida.
Aquí está la diferenciación entre los sistemas, en el impacto que va a generar en la vida de quienes se vean afectados.
P. ¿De qué o de quién depende que un sistema sea válido para una aplicación?
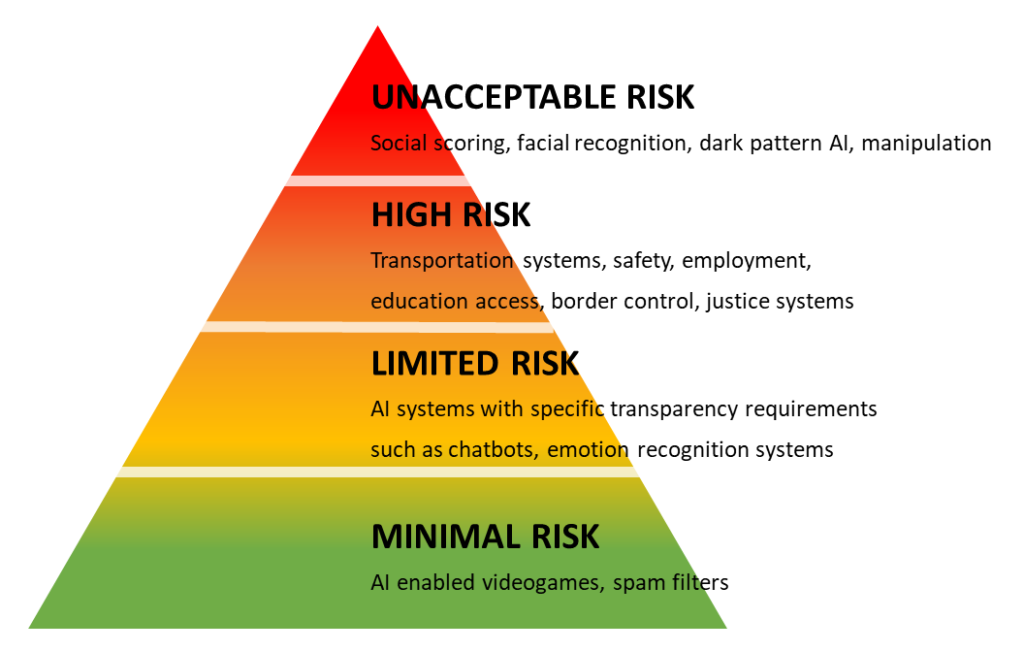
R. Se está intentando estandarizar y expandir el uso de lo que se conoce como el semáforo de la regulación de la IA. Es un semáforo que sirve para diferenciar entre sectores y casos de uso, y no algoritmos. Realmente, los algoritmos pueden ser los mismos, pero, el sector en el que se vaya a usar sí que hace que tenga un matiz diferente.
Lo que persigue la Unión Europea es divulgar este sistema. Consiste en clasificar tu modelo ya preparado para usarse -no el algoritmo- en una de las cuatro categorías que se han creado. El semáforo va desde el “riesgo mínimo” hasta el “riesgo inaceptable”. Por ejemplo, el uso que Netflix le da a un modelo estaría en la faceta mínima. Conforme vas escalando en ese semáforo aparecen otras áreas como sistemas de reconocimiento emocional. Este, en concreto, está demostrado que no está tan resuelto y no es tan sólido, en tanto que la estandarización de las emociones depende, entre otros factores, de las diferentes culturas del planeta. Conforme sigues subiendo aparecen la seguridad, educación, transporte, control de fronteras…
Este modelo consigue estandarizar los usos. Lo que se quiere transmitir es que no depende de que utilices la técnica más novedosa, sino de a quiénes va a impactar tu sistema. Esta característica es la única que se puede catalogar.
P. Y los datos, ¿de qué manera se pueden extraer de un sistema? ¿Cómo se trabaja para que los modelos inteligentes no retengan datos?
R. El control de datos ya en sí es difícil. Aquí es pertinente hablar de la gobernanza del dato.
Todas las empresas que trabajen con datos tienen que tener un sistema de gobernanza del dato. Es decir, que si trabajan con datos de terceros han de tener una trazabilidad, integridad y accesibilidad total del dato. De este modo pueden saber quién ha accedido al dato, si lo podía haber hecho o no, cuándo lo ha hecho…
Todo este engranaje facilita el proceso de borrado de datos. Si un usuario reclama sus datos a una compañía, una arquitectura de este tipo permitirá no solo encontrarlo fácilmente, sino poder seguir el rastro de los lugares o entornos por los que ese dato ha pasado para eliminar también sus huellas. Esta es la complejidad del borrado de datos: eliminar todo su rastro. Para ello, un sistema de gobernanza de datos es esencial.